


AIエンジニアとして AI の技術を学ぶのはもちろんですが、AI の歴史も学ぶことで知識を活かした仕事ができると思います。
歴史を見てみると、AIブームは過去3回起きています。それぞれのブームは以下のグラフのタイミングで起きています。そしてこのグラフから分かるように、現在は3度目のブームの真っ最中になります。
今回は、それぞれのブームから AI の知識を深めるきっかけにしてもらえればと思います。
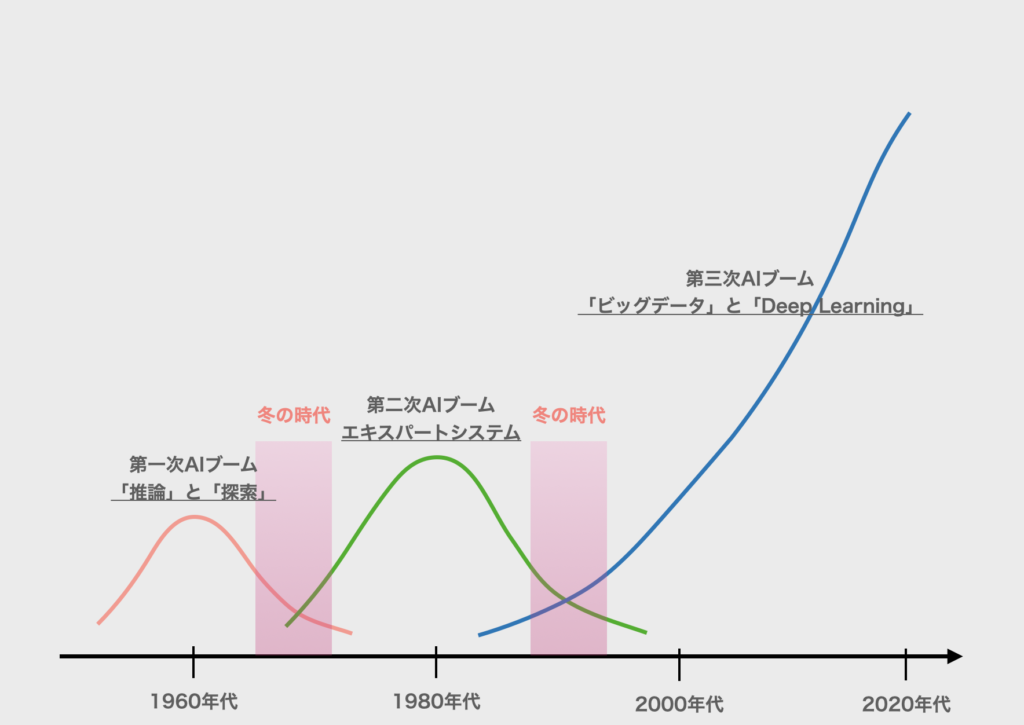
まず1回目は 1950年代後半~1960年代に「推論」と「探索」の研究が進みました。
1回目:「推論」と「探索」(1950年代後半~1960年代) 「推論」で思考パターンを分析し、「探索」で目的の解を導き出す研究が進みました。コンピュータの計算は、人間には追いつけない高速な処理になるので、人間が考え出すよりものすごく速く解にたどり着くことに注目されました。パズルや迷路、将棋など、ものすごい速さで計算をします。 ただ、これは予め決まったパターンが存在していることが前提になります。パズルや迷路、将棋には解法があります。コンピュータは決まったパターンを計算しているに過ぎませんでした。一方で、人間の世の中はパターン化できない曖昧なことがたくさんあります。 ここが1回目のブームの限界となり、やがて下火になりました。
次に2回目は 1980年代に「エキスパートシステム」の研究が進みました。
2回目:「エキスパートシステム」(1980年代) 「エキスパートシステム」とは文字通り、専門家の知識を有した AI になります。予め専門家の知識を登録しておき、その登録した知識の組み合わせから解を導き出します。登録した知識とそれに対応する解が現実的なものであれば、人間の世の中でも十分使えるものになります。このことは非常に画期的でしたが、知識と対応する解の登録は人手になります。特定の分野であれば可能でも、無限とも言える人間の世の中の情報を人手で登録することは不可能です。 ここが2回目のブームの限界となり、やがて下火になりました。 ちなみに私も、学生自体に Prolog の授業を受けたことがあります。
そして、2000年代から現在まで「ビッグデータ」と「Deep Learning」の研究が進んでいます。
3回目:「ビッグデータ」と「Deep Learning」(2000年代〜現在) 「ビッグデータ」とは文字通り、大量のデータになります。インターネットの普及により世の中から大量のデータを収集できる仕組みが生まれました。加えて「Deep Learning」がAI技術を発展させました。ビッグデータを元に、Deep Learning という技術を活用した AI が成長しました。Deep Learning の構想自体は以前より考えられていましたが、Deep Learning は当時のコンピュータには不可能な、膨大な計算が必要でした。コンピュータ、特にGPUの性能が飛躍的に向上したこともブームの一因と言えます。Deep Learning の概要については、後の記事で説明しようと思います。
ちなみに、Deep Learning が華々しく世にデビューしたきっかけは、ImageNet と呼ばれる大量の画像をカテゴリに分類するコンペティション、ILSCRC(ImageNet Large Scale Visual Recognition Challenge)において、前年度2011年のエラー率が26%(2010年が28%)だったのに対し、2012年にトロント大学のチームが Deep Learning を用いてエラー率17%としたことになります。今までは毎年1%台のエラー率改善をコツコツ行っていたのに対し、いきなり10%もの向上となったのは衝撃を与えました。以降の年は、上位の手法がすべて Deep Learning に置き換わり、2015年には人間のエラー率をも上回りました。
ILSVRCについては、以下のサイトの方が詳しく書いています。
ILSVRC を振り返り CNN を deep に理解する①
現在も第三次AIブームは続いていて、日々 Deep Learning の研究は続いています。Deep Learning の登場で人間の世の中の曖昧さが表現できるようになったことで、活躍する場は格段に増えました。これからAIエンジニアとして活躍していく上で、この Deep Learning をメインに使用していくことになります。そして AI の歴史を学ぶことで、この Deep Learning が注目されている理由などもより深く知ることができると思います。引き続き、AIエンジニアとしてスキルアップを目指しましょう!

